In one of our projects using an Event Sourced design, we found ourselves paying an unacceptable and growing cost for reading events. This was less a problem when loading an aggregate root into memory, but a significant problem when rebuilding read models. The read models most affected were those that had to read in the large number of ledger transactions.
The current implementation of the event store on the project is a Sql Server + blob storage hybrid solution hosted on Azure. Sql Server stores the event meta data such as SequenceId, Message Type, AggregateType (aka SteamType) and AggregateId (aka StreamId). The actual content of the event is stored in Azure Blob storage (Azure’s equivalent to AWS S3). This design has served the team well providing an easy to understand, fast scalable solution. At time of writing the largest deployment of this has nearly half a billion events weighing in at 3TB.
The problem we were facing was that recreating read models was taking longer than a weekend. Much longer. This delay takes away from the team the ability to quickly pivot and deliver results to the business. One of the key benefits that a CQRS read model should give us is the ability to quickly recreate and query customized views of the data.
There were numerous issues at play, but this post looks at how a change in the serialization technology choice and the way we used it gave some significant gains.
Starting with JSON
JSON is the serialization format du jour. It is human readable, schema-less and allows partial deserialization. It is the language of the web.
Partial deserialization/Proxy types
One of the things we did as standard practice was to use a centralized Contracts library of .NET types to facilitate serialization and deserialization. This was a productivity boost, but I was curious as to how this impacted performance. In many, if not most cases, a read model would only need to use a small part of the payload for a JSON message. However, as we used these strongly typed Contracts, we would always parse and deserialize the whole JSON object. While this seems like a small cost, when inspecting some of our messages, they could contain large graphs and arrays of transactions and repayment schedules.
Leaning on the schema-less features of JSON, we tested what the difference was in using a customized Type specific to our read model to deserialize into. A sample event that we looked at was our MonthlyFeeChargedEvent, which at the root had 14 properties, 1 of which was an array of objects. For the purposes of our read model, we only needed to access 5 of these properties, and not the array. The difference in performance surprised us. We saw 3x improvement in speed to deserialize (160us to 50us).
While I was excited, the team were less impressed. So we ran some numbers. If of our +400M events, 25M were required by a given read model to be recreated, how long do I have to process each event? To process 25,000,000 in 2days gives us an average of less than 7ms for each event. If you want to see this reduced to 2hrs, you have less than 300us (0.3ms) per event. Now considering I need to also perform a read and a write in this 300us, I don’t want to spend half of that just deserializing data. That then made me think about reducing the size of data we had to read.
Reducing I/O
When I started Web development in the late 90’s XML was the format to use. These days, poor old XML is laughed at if proposed as a messaging format due to its bloated size. This bloat is mainly due to it being human readable text format. However, JSON is also a human readable text format. Human readable formats are great for config files edited by humans, but seem pointless to me for a messaging format. A computer will be required to send, receive and store the data, in which case a computer could also provide a pretty print facility if required for a human to consume.
Considering an average message size of 9KB and assuming we need to process 25,000,000 messages, that would require reading just under 220GB of data. Even on a gigabit connection that takes half an hour to transfer.
With this in mind, we went looking for a format that had the same properties as JSON (schema-less, and partial deserialization) but was smaller and we could let go of the human readable requirement. BSON seemed to be an obvious choice. On quick inspection however it provided tiny improvements on serialization size for our data, and had no improvement on deserialization time. We also needed .NET support as we are a C#/.NET team. My search took me to a format called MessagePack. There were two popular libraries for MessagePack on Nuget. So I pulled them into my Benchmark suite that I tested JSON partial deserialization on.
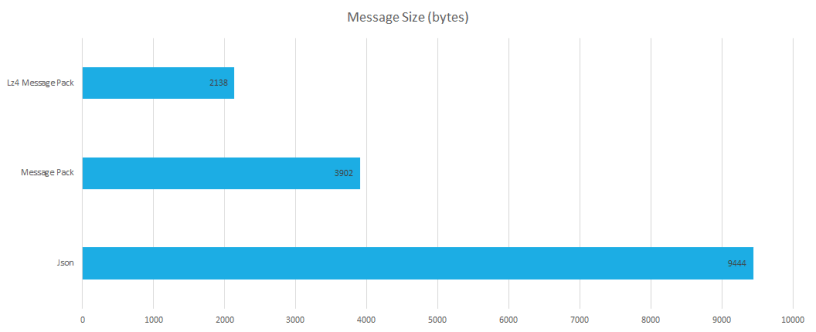
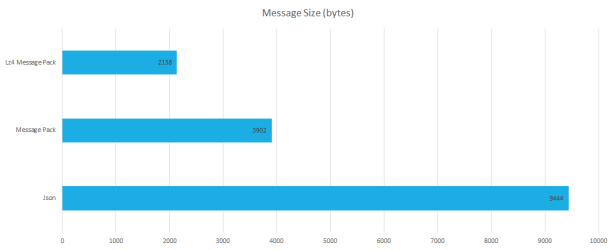
First, I had to see what size improvements I would get by adopting MessagePack. The results were pleasing. Our 9,444byte sample message could be reduced to 3,902byte (2.4x improvement). That meant 2.4x less disk requirements, but more importantly 2.4x less I/O requirements to read from disk and then push across a network. What we found next was a very pleasant surprise. One of the libraries also provided Lz4 compression as a built-in feature. This reduced our sample message size to 2,138byte, a further 1.8x improvement for a total of 4.4x size reduction! That would reduce our 3TB dataset to less than 700GB! All of this without any significant changes to our code. We didn’t need to decorate our types with attributes, or create schema or any IDL.
The next question was, would this improvement in file size come at the cost of deserialization? Using our existing benchmark, we added the two MessagePack libraries. We compared using the full Contract Type, and a reduced custom Proxy type. We compared the Lz4 compressed option too.
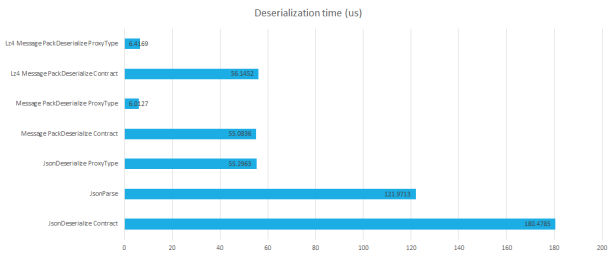 These results were brilliant. Not only would we get a reduced data size by adopting MessagePack+Lz4 compression, if we also used a Proxy Type (with just the properties we wanted to access) we could also get a 28x improvement in deserialization speed!
These results were brilliant. Not only would we get a reduced data size by adopting MessagePack+Lz4 compression, if we also used a Proxy Type (with just the properties we wanted to access) we could also get a 28x improvement in deserialization speed!
Conclusion
To summarize these numbers, we have just under 500,000,000 events taking up 3TB of space. To rebuild one of our read models we needed to consume 25,000,000 of these events which was approximately 225GB. The theoretical time to transfer this data across a gigabit network was just over 29 minutes. Then it would take 1 hour 15min to deserialize all the data. That is 1 hour 45min to read and parse the required data. Also remember that is a theoretical best case.
After adopting the Lz4 compressed message pack format those 25,000,000 events are reduced to 50GB, which would take just under 7min to transfer on a gigabit network. Deserialization would then take only 2minutes 42seconds. Total time to transfer and deserialize is reduced by a factor of 11; from 1h45m to just 9 minutes!
Now clearly this was only one contributing factor to our rebuilds that were taking over 2 days, but it showed that if we challenge our assumptions, we can make large gains.
Further reading:
Event Sourcing
https://martinfowler.com/eaaDev/EventSourcing.html
https://docs.microsoft.com/en-us/azure/architecture/patterns/event-sourcing
https://leanpub.com/esversioning
http://subscriptions.viddler.com/GregYoung
https://github.com/SQLStreamStore/SQLStreamStore
MessagePack
https://github.com/neuecc/MessagePack-CSharp

Great post Lee, thanks for sharing. Interesting idea to only parse what is needed for the particular view. Will have to keep that in mind for our system.
I’ve always wondered, generally speaking, how read-model regeneration (new or old) would work out as the number of events got larger and larger…
BTW, I suggest perhaps XML wasn’t made to be human readable but rather easily parsed by a generic parsers. Of course, also text format for humans.
LikeLike
For those interested in the benchmarks for the various formats, you can find it here – https://github.com/LeeCampbell/SchemalessSerializationBenchmark
LikeLike
(Reading this a bit late), but it’s great!
These types of optimisations are so often overlooked.
LikeLike