I had the pleasure last year to meet with Gil Tene, an authority on building high performance software and specifically high performance JVM implementations. He gave a brilliant presentation at React San Francisco and then again at YOW in Australia on common mistakes made when measuring performance. He he explained that measuring latency is not about getting a number, but identifying behavior and characteristics of a system. Often when we set out to measure the performance of our software we can be guided by NFR (Non-Functional Requirements) that really don’t make too much sense. More than once I have been presented with a requirement that the system must process x requests per time-period e.g 5 messages per second. However as Gil points out this single number is either unreasonable, or misleading. If the system must always operate in a state to support these targets then it may be cost prohibitive. This requirement must also define 100% up-time. To work around that, some requirements specify that the mean response time should be y. However this is potentially less useful. By definition what we are really specifying is the 50% of requests must see worse performance than the target.
A useful visualization for pointing out the folly of chasing a mean measurement is illustrated below.

[Source – https://en.wikipedia.org/wiki/Anscombe%27s_quartet]
All of these charts have the same mean value, but clearly show different shapes of data. If you measuring latency in your application and were targeting a mean value, you may be able to hit these targets but still have unhappy customers.
When discussing single-value targets, a mean value can be thought of as just the 50th percentile. In the first case the requirement was for the 100th percentile.
Perhaps what is more useful is to measure and target several values. Maybe the 99th percentile plus targets at 99.9% and 99.99%, etc., are what you are really looking for.
Measuring latency with histograms
Instead of capturing a count and a sum of all latency recorded to then calculate a mean latency, you can capture latency values and assign them to a bucket. The assignment of this value to a bucket simply increments that bucket’s count. This now allows us to analyse the spread of latency recordings.
The example of a histogram from Wikipedia shows how to represent heights by grouping into buckets of 5cm ranges. For each of the 31 Black Cherry Trees measured, the height is assigned to a bucket, and the count for that bucket is increased. Note that the x axis is linear.

A naive implementation of a histogram however, may require you to pre-plan your number and width of your buckets. Gil Tene has helped out here by creating an implementation of a histogram that specifically is design for high dynamic ranges, hence its name HdrHistogram.
When you create an instance of an HdrHistogram you simply specify
- a maximum value that you will support
- the precision you want to capture as the number of significant digits
- optionally, the minimum value you will support
Application of the HdrHistogram
When Matt (@mattbarrett) and I presented Reactive User Interfaces, we used the elements of drama and crowd reaction to illustrate the differences between various ways of conflating fast moving data from a server into a client GUI application. To best illustrate the problems of flooding a client with too much data in a server-push system, we used a modestly powered Intel i3 laptop. This worked fairly well in showing the client application coming to its knees when overloaded. However it also occasionally showed Windows coming to its knees too, which was a wee bit too much drama to have on stage during a live presentation.
Instead we thought it better to provide a static visualization of what was happening in our system when it was overloaded with data from the server. We could then contrast that with alternative implementations showing how we can perform load-shedding on the client. This also meant we could present with a single high powered laptop, instead of bringing the toy i3 along with us just to demo.
We added a port of the original Java HdrHistogram to our .NET code base. We used it to capture the latency of prices from the server, to the client, and then the additional latency for the client to actually dispatch the rendering of the price. As GUI applications are single threaded, if you provided more updates than the GUI can render, there are two things that can happen:
- updates are queued
- updates are conflated
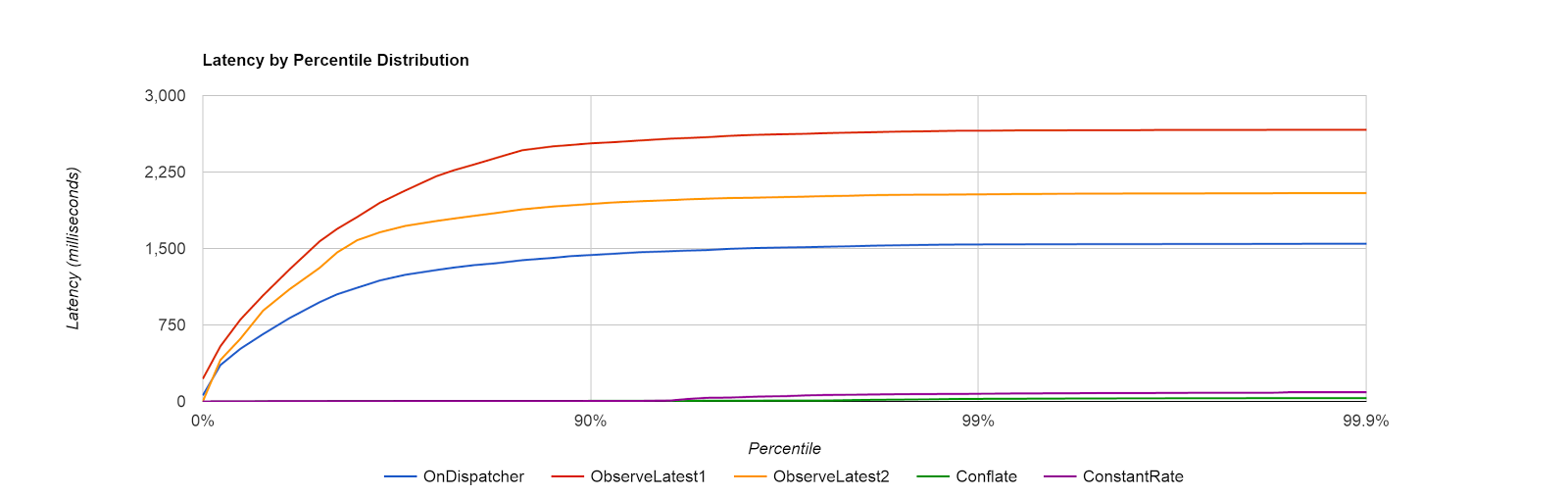
We had two problems. The first problem was an assumption that what worked for Silverlight, would also work for WPF. As WPF has two threads dedicated to presentation (a UI thread and a dedicated Render thread), we were actually only measuring how long it took for us to put a price on another queue! You can see that the ObserveLatest1 and ObserverLatest2 (red and yellow) lines show worse performance than just processing all items on the dispatcher. I believe this is due to us just doing more work to conflate before sending to the render thread. Unlike in Silverlight, once we send something to the Render thread in WPF we can no longer measure the time taking to actually render the change. So our measurements here were not really telling us the full story.
The second problem we see is that there was actually a bug in the code we copied from our original silverlight (Rx v1) code. The original code (red line) accidentally used a MultipleAssignmentDisposable instead of a SerialDisposable. The simple change gave us the improvements seen in the yellow line.
We were happy to see that the Conflate and ConstantRate algorithms were measuring great results, which were clearly supported visually when using the application.
To find out more about the brilliant Gil Tene
- see his talk at React San Francisco and then again at YOW in Australia
- check out his web site – http://latencytipoftheday.blogspot.co.uk
- follow him on twitter @giltene
- see his content on infoQ – http://www.infoq.com/author/Gil-Tene
- or look at Azul (https://www.azul.com/) and the things they can make Java code do

Hi Lee. Is RX development still under progress. Can I assume forum support / commercial support continue to be available for another few years, so I recommend use of RX in our WPF product.
LikeLike
Hi HM. I have no official association with the Rx.NET team so cany comment on what Microsoft will do in the future. However if I was starting a Xaml/WPF project that needed Rx features I wouldn't hesitate to use it. The library has benn solid for 5 years now and has loads of *community* support (stackoverflow.com, blogs, talks etc)
LikeLike